以前Difyを使ってインタビュー記事化のフローを構築しましたが、しょっちゅうAPI Rate Limitのエラーで怒られてました。プロンプトが長いのはわかっているのですが、似た長さでも起こるときと起こらない時があるので苦戦しました。
結論
待機時間を作って解決しました。改めて考えたらRate Limitなので当たり前でした。
エラー内容
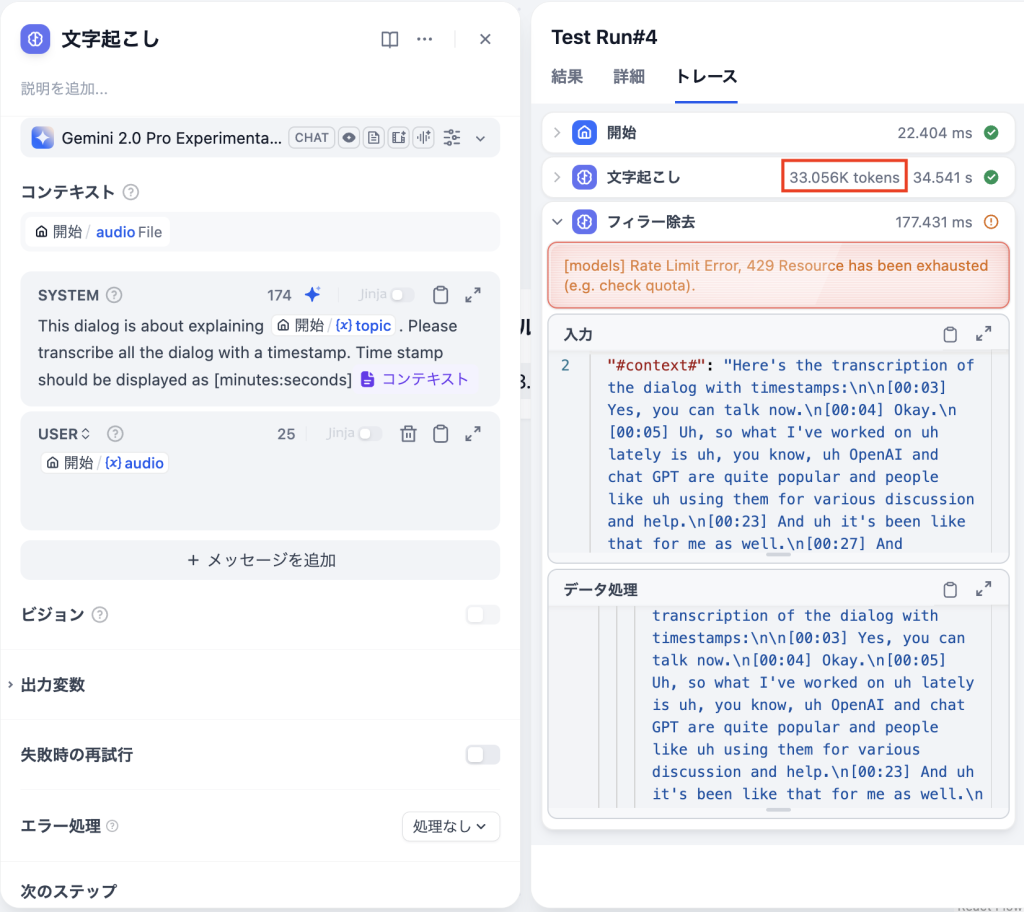
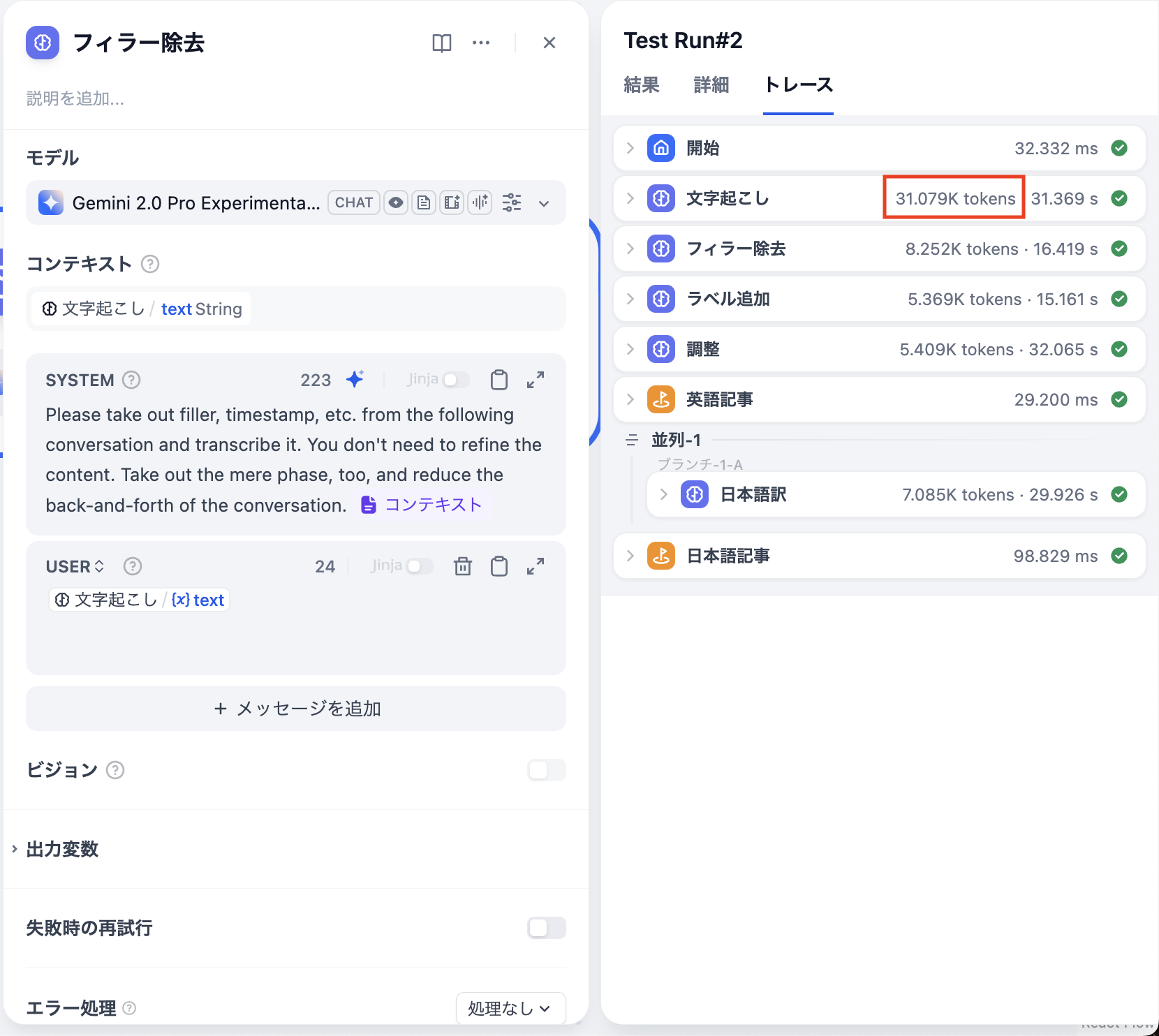
文字起こし用の音声ファイルの長さが31Kトークンの場合は正常に処理できましたが、33Kトークンのときはエラーが発生しました。 (※詳細は画像参照)
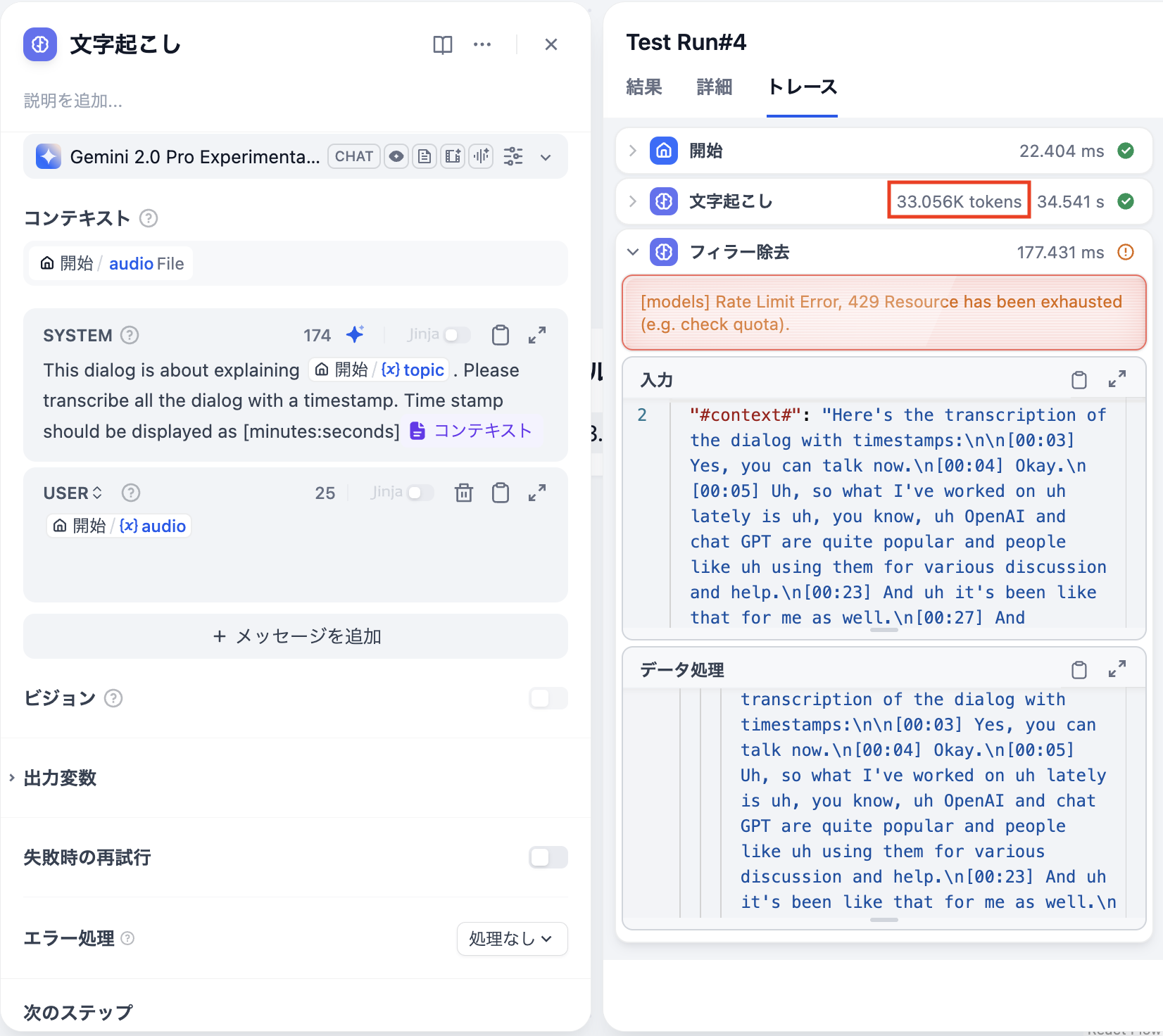
エラー文
[models] Rate Limit Error, 429 Resource has been exhausted (e.g. check quota).プロンプト変更による対策
まず、元の音声データを分割すればよいと考えたものの、根本的な解決策ではないので処理中の文章も詳しくチェックすることに。そこで、「データ処理」の部分をテキストに貼り付けてみたところ、以下のようになりました。

SYSTEMとUSERの両方に文字起こしのテキストを貼り付けていたためプロンプトの文章量が二倍になっていました。
そこで、プロンプトをSYSTEMだけにし、音声ファイルをビジョンの欄に貼り付けることにしました。
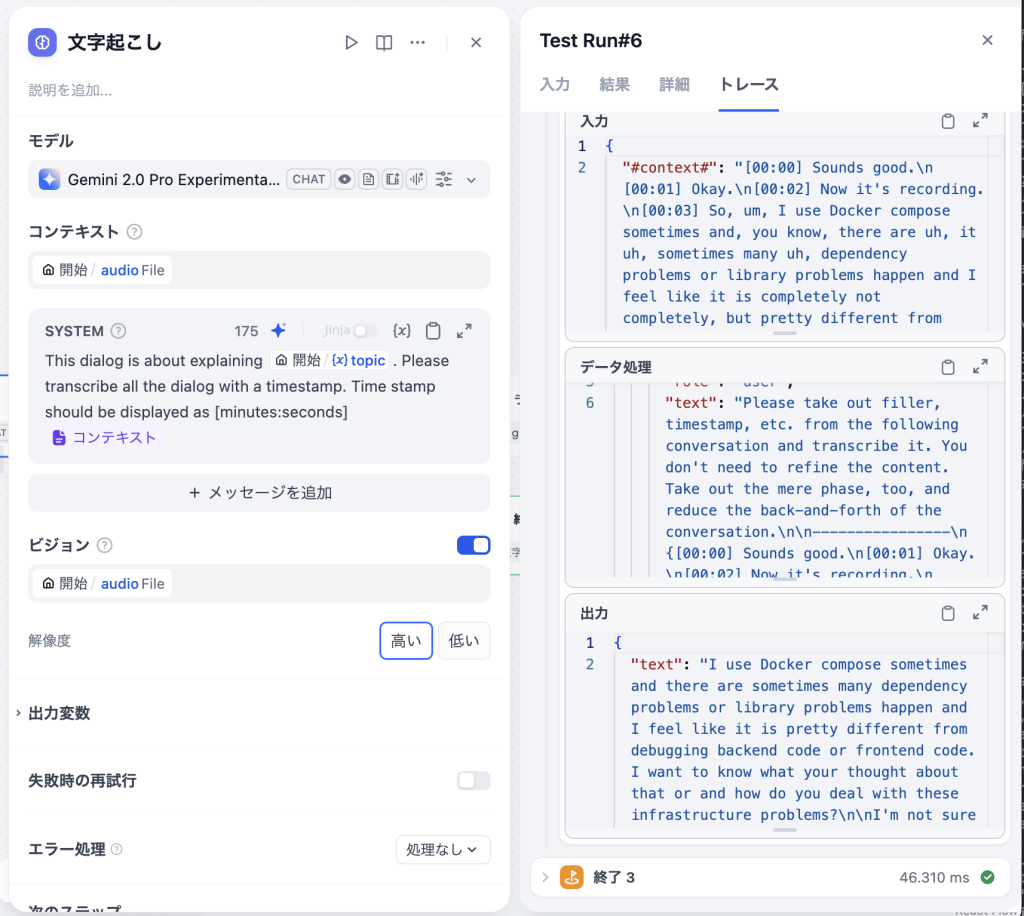
しかし、それでも同じエラーが出たため別の対策をすることに。
待機処理による対策
問題はデータ量ではなく「短時間に大量のデータを送信していること」だと見立て、待機処理を設けてみることにしました。Difyには待機ブロックがないため、コードブロックに待機処理を組み込むことにしました。
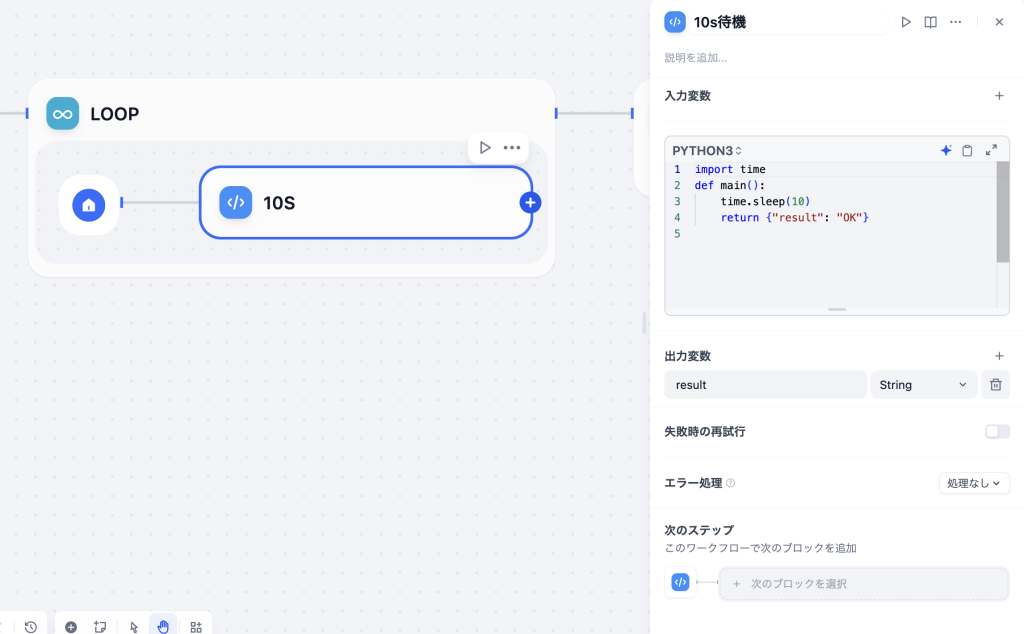
import time
def main():
time.sleep(10)
return {"result": "OK"}長時間の待機は処理時間超過と判断され強制終了されるため、10秒待機を複数回繰り返し、合計40秒の待機時間を設けました。その結果、最終的にエラーを回避することに成功。
今後の課題
フィラー除去や翻訳の作業はGeminiではなくChatGPTに実行させたかったものの、文章量が多すぎて一部しか処理してくれなかったため、依然として課題が残っています。これはAPIの制限に達したわけではないため、完全に自動化するならフロー内でデータを分割する必要がありそうです。